Select Language:
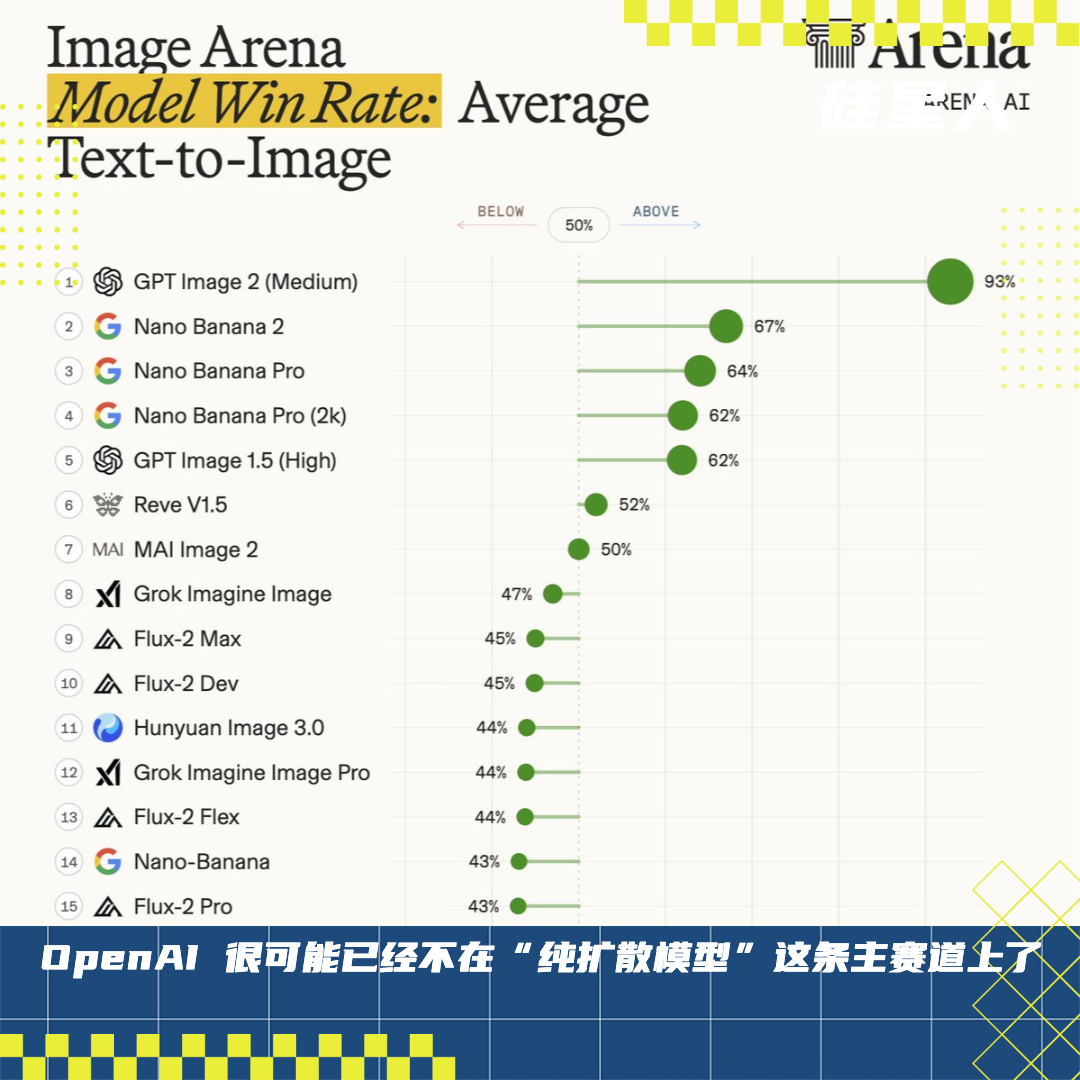
Recent developments in AI image generation have sparked widespread curiosity about what makes GPT Image 2 so remarkably powerful. Is it just another iteration of diffusion models? Did the team increase the parameter count from 7 billion to 20 billion with DiT? Or perhaps they trained on even larger, higher-quality datasets? While all these factors contribute, they don’t tell the full story.
Based on conversations with industry insiders and technical analyses, there’s a clearer trend emerging: OpenAI may have shifted away from focusing solely on diffusion models. Instead, they are likely orchestrating a new paradigm that leverages large language models (LLMs)—most probably GPT-4o—as the primary driver behind image understanding and generation. In this approach, the diffusion component or another decoding method handles pixel-level synthesis, but the core semantic planning stems from an advanced LLM that comprehends instructions, context, and object relationships.
Supporting this hypothesis are two key clues. First, the model itself appears to declare its identity. When examined through content verification methods, metadata attached to images generated by GPT Image 2 explicitly references GPT-4o. Second, forensic analysis of metadata extraction reveals a digital signature indicating GPT-4o’s involvement, suggesting that the model’s architecture integrates an LLM component directly into its pipeline. This integration could explain the dramatic performance gains observed.
Diving deeper, the shift from pixels to semantically rich tokens reveals crucial insights into the model’s capabilities. Historically, text-to-image AI has faced a persistent challenge: translating precise, nuanced language into visual content. Models like Midjourney, Stable Diffusion, and DALL·E excel at stylistic control but stumble over text rendering—sometimes producing gibberish or inconsistent characters. This weakness roots in the fundamental working principles of diffusion models, which are designed to reconstruct textures and styles through iterative noise removal. They excel at creating realistic textures but struggle with representing discrete, symbolic elements like letters.
The core reason lies in how diffusion models handle image creation—they consider images as continuous textures that can be probabilistically approximated. When asked to generate text, which is inherently discrete, the models find it difficult because they are not optimized for symbol accuracy. Their denoising steps are probabilistic estimations best suited for realistic textures rather than precise character shapes. As a result, text often appears distorted or nonsensical.
GPT Image 2’s breakthrough appears rooted in reimagining images as language-like semantic tokens—what researchers are calling a “semantic密语(cipher)”. Instead of treating images solely as pixel arrays, the model converts images into a sequence of tokens in a shared semantic space that aligns with language embeddings. This is achieved through a sophisticated tokenizer that can compress an image into a compact, information-rich representation comparable to text. When an image is expressed as a sequence of tokens, it becomes amenable to the same probabilistic modeling techniques used for language.
This process involves two intertwined components: a sensory-perception tokenizer that encodes images into tokens, and a generative model—most probably GPT-4o—that predicts or adjusts these tokens based on instructions. Because both text and images are represented in this shared semantic space, the model can seamlessly manipulate visual concepts through language commands, adjusting objects, styles, or layouts much like rewriting a sentence. This enables a level of semantic understanding and multi-turn editing far beyond what traditional diffusion methods can achieve.
Another key realization is that you don’t necessarily need pixel-by-pixel diffusion to produce high-quality images. Instead, the workflow likely involves a two-step approach: first, the language model predicts the semantic tokens that define the scene, then a specialized decoder or diffusion module converts these tokens into detailed visuals. This hybrid approach balances semantic accuracy with visual fidelity, combining the best of both worlds.
In terms of training, the remarkable scene of GPT-4o self-educating its image generation abilities unfolds through a self-reinforcing data cycle, often called a “data flywheel.” Essentially, OpenAI leverages GPT-4o’s advanced image understanding to generate detailed annotations for massive datasets—sometimes even surpassing manual labeling in finesse. These pseudo-labels are then filtered through a rigorous quality assurance process, ensuring only the most relevant and high-quality data feeds back into training the next iteration. This recursive loop enables the model to continually refine its understanding, reducing reliance on expensive human annotation and exponentially improving its performance.
But how does GPT-4o itself get better at image understanding? The answer points toward a combination of training on colossal datasets—comprising billions of images and captions—and a process akin to “self-supervised learning.” GPT-4o, capable of detailed image description, can generate high-dimensional semantic labels for unannotated images, effectively “teaching itself” what various visual features mean. This self-labeling, combined with strict sampling methods that select only the most promising data, creates a self-improving cycle that boosts the model’s abilities over time.
Further complexity arises in the multi-faceted quality checks implemented via Reinforcement Learning from Human Feedback (RLHF). In the language domain, RLHF effectively guides models to align outputs with human preferences. Extending this into the visual realm involves evaluating images on several axes: aesthetic appeal, fidelity to prompts, and safety considerations. Balancing these sometimes conflicting criteria requires translating complex human judgments into structured feedback mechanisms, often leveraging the same language-anchored understanding that GPT-4o wields. This unified semantic approach streamlines the feedback process, making it more effective and scalable.
Another intriguing aspect is the engineering behind maintaining faster inference speeds despite increasing model complexity. Traditional step-by-step diffusion processes are computationally intensive, especially for high-resolution images. However, GPT Image 2 seems to employ a hybrid inference strategy—using a sort of “coarse-to-fine” process—where initial semantic planning is rapid, followed by selective, high-fidelity refinement. Techniques like “speculative decoding” or leveraging a smaller, auxiliary network for initial drafts that are then verified or polished by a larger, more capable model help bridge performance gaps, enabling high-quality outputs without sacrificing speed.
Contrast this with earlier approaches reliant solely on diffusion, where image quality improvements came at the cost of longer generation times. GPT Image 2’s speed gains suggest a fundamental architectural shift: moving the heavy lifting of semantic reasoning into an efficient language model, which greatly accelerates the overall process.
Finally, the true game-changer may be the integration of interactive, dialog-based refinement with Image GPT. Instead of users crafting detailed prompts and iterating through trial-and-error, conversational interfaces empower users to clarify desired outcomes incrementally. The model utilizes the context from previous interactions, understanding subtleties of user intent and adjusting images dynamically. This creates a more natural, intuitive experience—bridging the gap between human imagination and AI capabilities—while reducing frustration caused by the current trial-and-error cycle.
In conclusion, GPT Image 2 exemplifies a fundamental shift: moving away from a paradigm that treats image generation as a purely pixel-based problem. Instead, it embraces a unified semantic model that leverages large language understanding, self-supervised learning, and hybrid rendering techniques. This evolution points toward a broader vision of a “world model”—a comprehensive digital understanding that seamlessly integrates language, vision, and reasoning—signaling a new era in AI capabilities.