Select Language:
Running an AI model offline might sound like an innovative idea, yet it usually demands robust and pricey hardware. That said, not all options fit this mold. The R1 model from DeepSeek offers a practical solution for devices with less power, and its installation process is surprisingly straightforward.
What Does Running a Local AI Chatbot Mean?
When you interact with online AI chatbots like ChatGPT, your requests are processed via servers belonging to organizations like OpenAI. Consequently, your device doesn’t handle the heavy computing tasks, and you rely on an active internet connection to engage with these chatbots, which can compromise control over your personal data. AI chatbots powered by large language models, such as ChatGPT, Gemini, and Claude, are incredibly resource-intensive because they require GPUs with substantial VRAM. This is a primary reason why many AI models operate in the cloud.
A local AI chatbot, on the other hand, is installed directly on your device, similar to any standard software application. This allows you to use the chatbot anytime without needing an internet connection. DeepSeek-R1 is a local large language model (LLM) that can run on a variety of devices. Its compact 7B model, featuring seven billion parameters, is optimized for mid-range hardware, allowing me to generate AI responses without relying on cloud servers. In simpler terms, this results in quicker responses, enhanced privacy, and full governance over my data.
How I Installed DeepSeek-R1 on My Laptop
Setting up DeepSeek-R1 on your device is pretty straightforward. It’s worth noting, however, that you’ll be working with a less powerful version than DeepSeek’s web-based AI chatbot, which boasts around 671 billion parameters compared to DeepSeek-R1’s 7 billion.
To download and install DeepSeek-R1 on your computer, follow these steps:
- Visit Ollama’s website to download the most recent version. Install it like any other software application.
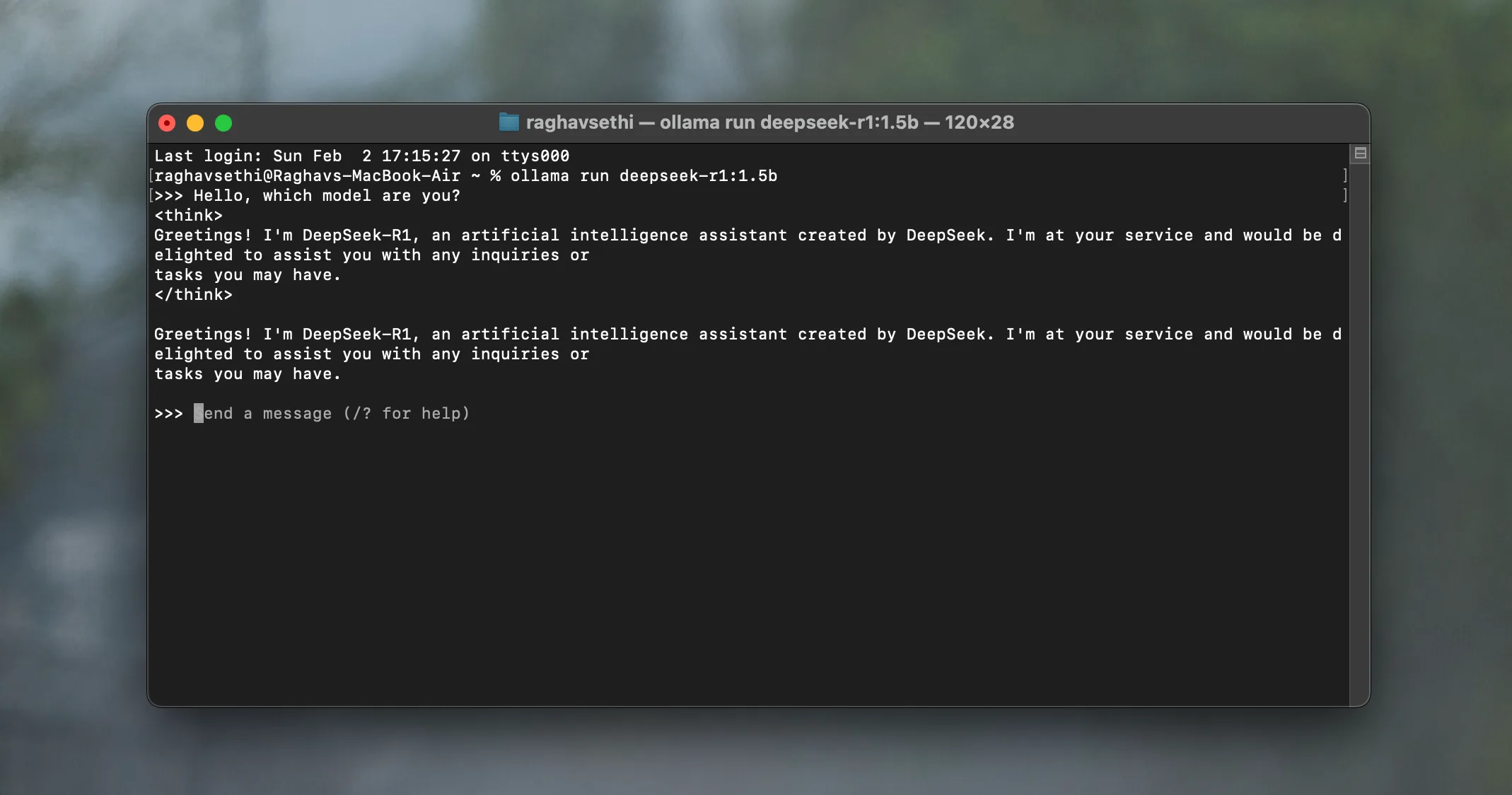
- Once installed, open the Terminal and enter the following command:
ollama run deepseek-r1:7b
This command will download the 7B DeepSeek-R1 model onto your computer, enabling you to enter queries directly in the Terminal and receive immediate responses. If you encounter performance issues, consider using a less demanding model by substituting 7b with 1.5b in the command above.
If you prefer a fully functional user interface with proper text formatting similar to ChatGPT, you might want to try an application like Chatbox.
Running DeepSeek Locally Isn’t Flawless, but It Gets the Job Done
As previously noted, responses from DeepSeek-R1 may not be as accurate or rapid as those from DeepSeek’s online chatbot, which operates on a more capable model in the cloud. Nonetheless, it’s worth examining how effectively these smaller models perform.
Solving Math Problems
To evaluate the performance of the 7B parameter model, I presented it with a mathematical equation and requested the solution to its integral. I was pleasantly surprised by its performance, particularly since simpler models often struggle with mathematical challenges.
Admittedly, this question wasn’t particularly complex, but that’s exactly why having an LLM available locally is so advantageous. It prioritizes accessibility for quick and straightforward inquiries rather than relying wholly on cloud solutions.
Debugging Code
One of the most valuable applications I’ve discovered for running DeepSeek-R1 locally is its utility in my AI projects. This is especially beneficial because I often code while traveling, where internet access may be limited, and I depend heavily on LLMs for debugging. To test its capabilities, I intentionally introduced an error in a piece of code.
X = np.array([1, 2, 3, 4, 5]).reshape(-1, 1)
y = np.array([2, 4, 6, 8, 10]) model = LinearRegression()
model.fit(X, y)
new_X = np.array([6, 7, 8])
prediction = model.predict(new_X)
It managed to navigate through the code without any issues, running smoothly on my M1 MacBook Air with just 8GB of unified memory (which is shared among the CPU, GPU, and other processing units).

While working with multiple browser tabs and an active IDE, my MacBook’s performance noticeably decreased. I had to force quit all running applications to regain responsiveness. With 16GB of RAM or a mid-tier GPU, you likely wouldn’t face these performance issues.
I also tested DeepSeek on larger codebases, but it got caught in a thinking cycle, so I wouldn’t recommend it as a full replacement for more powerful models. Still, it remains useful for quickly generating minor snippets of code.
Solving Puzzles
I was intrigued to see how well the model performs with puzzles and logical reasoning, so I utilized it to tackle the Monty Hall problem. It navigated through it effortlessly, but I grew to appreciate DeepSeek for an entirely different reason.

As evident from the screenshot, it doesn’t just provide an answer; it delineates the entire reasoning process behind it, demonstrating its capability to think through the problem rather than merely regurgitating a memorized response.
Research Work
A significant downside to operating an LLM locally is its limited knowledge base due to the outdated nature of its training data. Since it has no access to the internet, collecting accurate and timely information on recent events can be problematic. This limitation became particularly clear when I requested a summary of the original iPhone. The output was both inaccurate and amusing.

Clearly, the first iPhone did not launch with iOS 5 and there certainly wasn’t an “iPhone 3” that preceded it. The inaccuracies were abundant, and I faced similar issues when asking other straightforward questions.
Following a data breach with DeepSeek, I found solace in the ability to run this model offline, completely safeguarding my data from exposure. While it isn’t flawless, the advantage of having an AI assistant that operates offline is significant. I’m eager to see more models like this being implemented in consumer devices such as smartphones, especially in light of my recent dissatisfaction with Apple Intelligence.



