Select Language:
This past weekend, OpenAI rolled out its new o3-mini model, responding to the launch of China’s DeepSeek R1 reasoning model. The o3 series was first introduced in December of the previous year. OpenAI quickly released both the o3-mini and o3-mini-high versions to maintain its competitive edge in the AI landscape. Curious about how ChatGPT o3-mini performs compared to other AI models, we put it through extensive testing. We focused on its capabilities in coding and rigorously examined various benchmarks. Let’s explore our findings.
1. Outstanding Coding Capabilities
According to OpenAI, the o3-mini excels in coding tasks while ensuring low costs and high speed. Before its release, Anthropic’s Claude 3.5 Sonnet was the preferred model for coding queries. However, that could shift with the introduction of o3-mini, particularly its high-performance version available to ChatGPT Plus and Pro users.
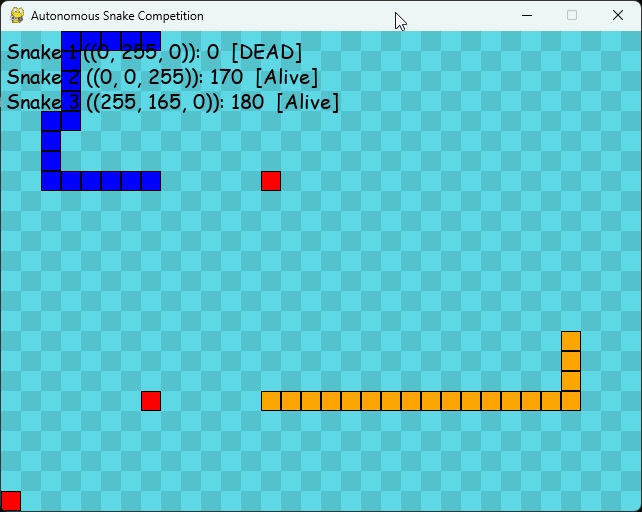
We tested the o3-mini-high model by asking it to develop a Python snake game featuring multiple automated snakes competing against each other. After approximately 1 minute and 10 seconds of processing, it generated the entire Python code in one go.
Upon executing the code, everything ran seamlessly without any glitches. It was entertaining to see the autonomous snakes move, exhibiting precision akin to human play!
The o3-mini-high model has achieved an Elo score of 2,130 on the Codeforces competitive programming platform, ranking it among the top 2,500 programmers worldwide. Moreover, in the SWE-bench Verified benchmark that measures real-world software problem-solving skills, o3-mini-high reached an accuracy of 49.3%, surpassing the larger o1 model (48.9%).
For those seeking AI coding assistance, I believe the o3-mini-high model currently provides the best performance until the full o3 model is released, which Sam Altman has mentioned is coming in the next few weeks.
2. Handling Challenging Math Problems
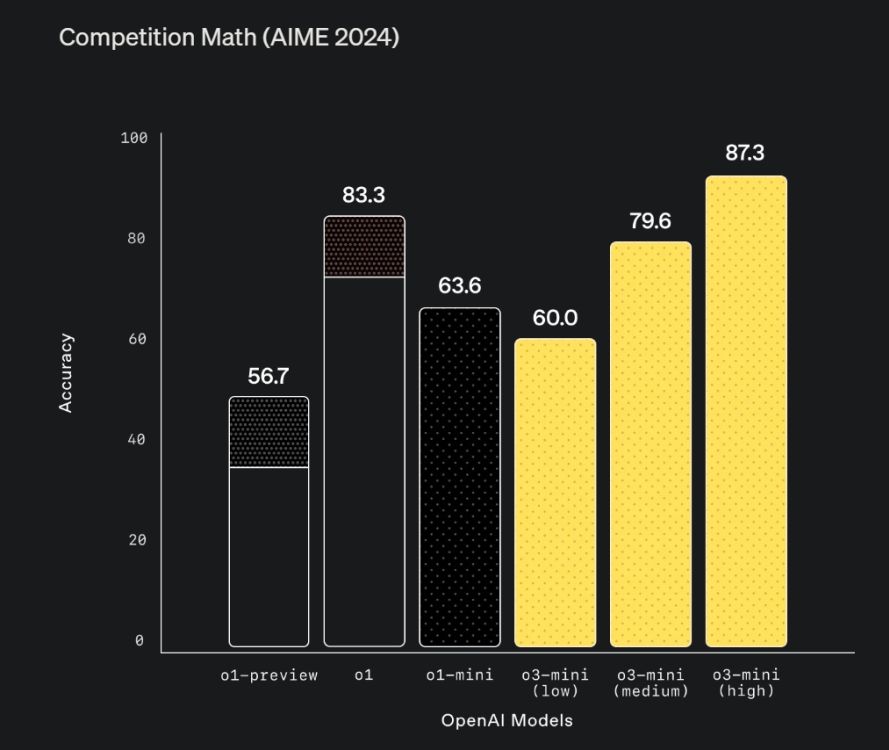
In addition to coding, the o3-mini model excels in mathematics. During the 2024 American Invitational Mathematics Examination (AIME), which includes questions across areas like number theory and geometry, o3-mini-high achieved an impressive score of 87.3%, outperforming the larger o1 model.
In the rigorous FrontierMath benchmark, which presents expert-level math problems designed by leading mathematicians and Fields Medalists, the o3-mini-high scored 20% over eight attempts. Even in just a single try, it achieved 9.2%, which is quite significant.
To put that in context, renowned mathematician Terence Tao has described the challenges posed by the FrontierMath benchmark as “extremely difficult,” often taking hours or even days for experts to solve. Other ChatGPT alternatives have only been able to reach about 2% in this benchmark.
3. Your PhD-Level Science Expert
The o3-mini-high model also stands out when tackling PhD-level science questions, leaving other AI models behind. The GPQA Diamond benchmark evaluates AI capabilities in specialized scientific fields, comprising advanced questions from biology, physics, and chemistry.
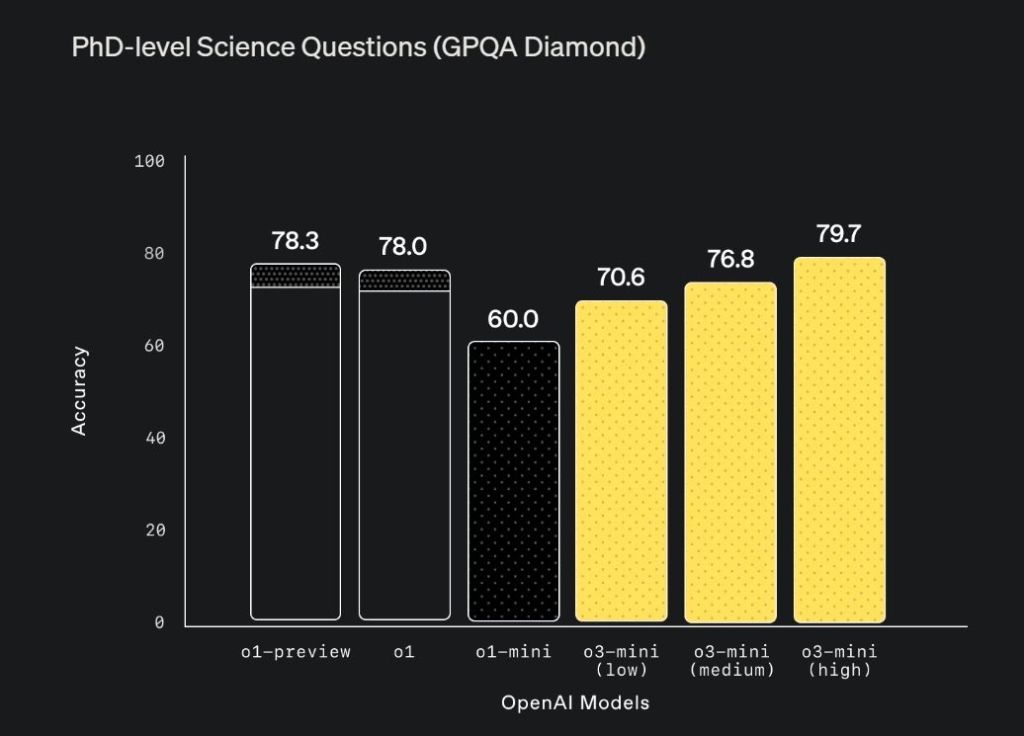
In the GPQA Diamond benchmark, o3-mini-high scored an impressive 79.7%, outperforming the larger o1 model (78.0%). For reference, Google’s latest Gemini 2.0 reasoning model achieved 73.3%, while Anthropic’s Claude 3.5 Sonnet reached 65% in the same benchmark.
This demonstrates that OpenAI’s smaller o3-mini model, when given sufficient time and computational resources, can excel in expert-level science questions compared to its competitors.
4. General Knowledge Performance
In terms of general knowledge, it’s expected that the o3-mini would fall short compared to larger models due to its smaller size and specialization in coding, math, and science. However, it performs impressively, nearly rivaling the larger models. In the MMLU benchmark, which tests AI performance across diverse subjects, o3-mini-high achieved a score of 86.9%, while OpenAI’s own GPT-4o scored 88.7%.
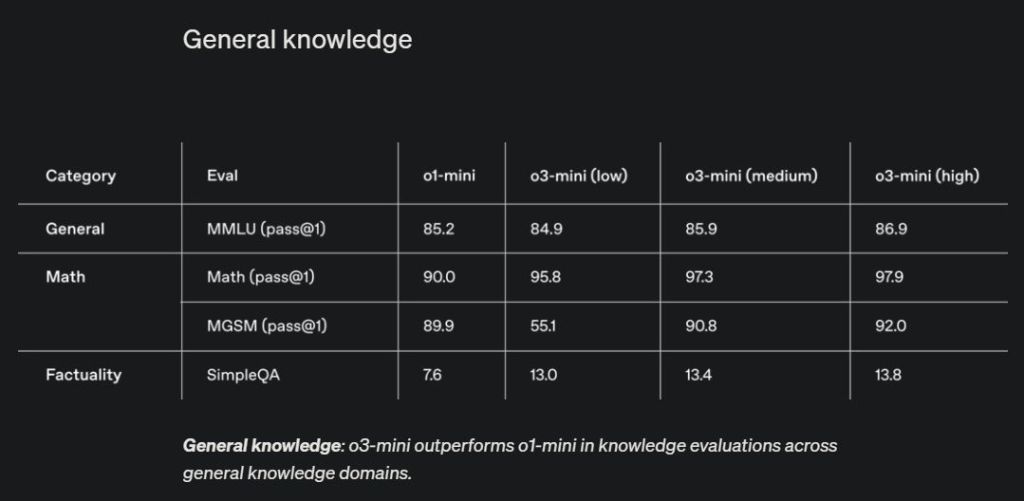
That being said, the upcoming larger o3 model is expected to outperform all existing AI models in general knowledge. The full o1 model has already achieved 92.3% in the MMLU benchmark. We are all looking forward to the release of the full o3 model, which could potentially dominate the benchmark entirely.
5. o3-mini Integrated with Web Search
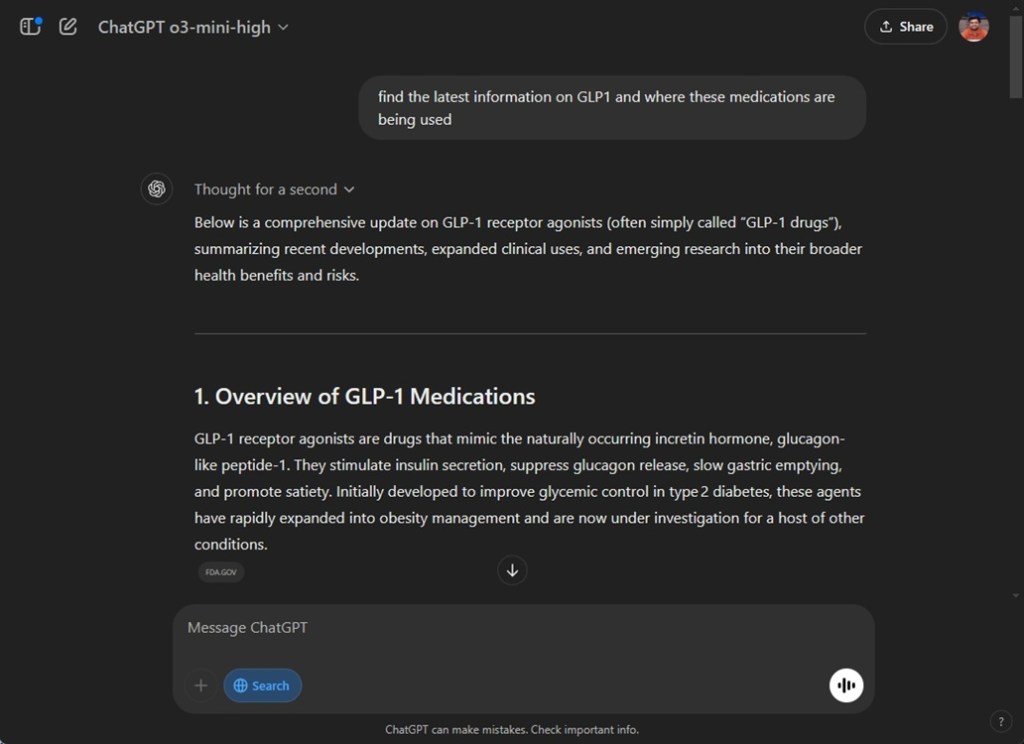
The o3-mini model has a knowledge cutoff in October 2023, which is relatively outdated now. However, OpenAI has included web search capabilities for the o3-mini model, enabling it to access current information online and perform advanced reasoning. While DeepSeek R1 offers similar functionality, no other reasoning model currently allows web integration for enhanced reasoning.
These are just a few of the advanced features of the o3-mini model. While free ChatGPT users can also utilize the o3-mini, the reasoning effort is limited to “medium” , utilizing less computational resources.
I recommend subscribing to ChatGPT Plus for $20 a month to take full advantage of the powerful ‘o3-mini-high’ model. It can be an invaluable asset for professional coders, researchers, and STEM undergraduates.


