Select Language:
The Chinese AI lab DeepSeek has recently unveiled its frontier R1 model, claiming it can rival or even outperform OpenAI’s ChatGPT o1 model. Already, DeepSeek has climbed to the top of the Apple App Store, surpassing ChatGPT. The impact of DeepSeek’s innovative and cost-effective model has also been felt in the U.S. tech stock market. To objectively assess the capabilities of both models, we’ve conducted a series of complex reasoning tests comparing ChatGPT o1 and DeepSeek R1.
ChatGPT o1 vs. DeepSeek R1: Misguided Attention
Large language models (LLMs) are often derisively referred to as “Stochastic Parrots” because they tend to rely on statistical pattern matching and memorization rather than true generalization. However, with advancements in AI technology, particularly with models like OpenAI’s o3, the narrative is shifting as these frontier models exhibit improved generalization and demonstrate emergent behaviors not explicitly programmed into them.
LLMs are trained on a variety of puzzles, riddles, and thought experiments. As a result, when posed with common riddles from their training data, these models typically utilize information from that corpus. Yet, when a puzzle is tweaked to mislead them, most LLMs struggle and simply repeat learned responses. This inability to adapt illustrates whether the AI is genuinely reasoning or merely recalling information.
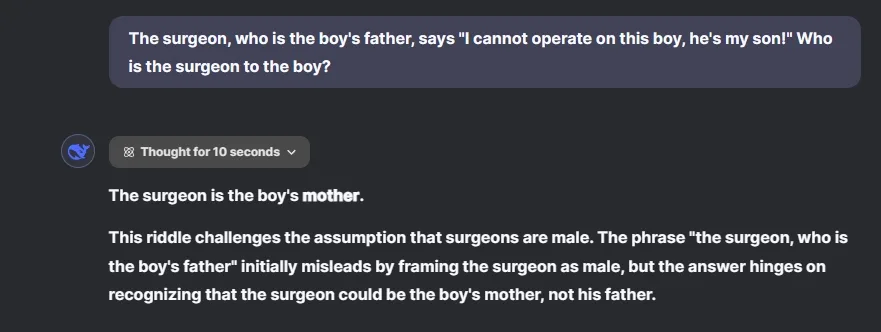
A surgeon, who is the boy's father, says, "I can't operate on this boy; he's my son!" Who is the surgeon to the boy?
In this scenario, the text clearly states that the surgeon is the boy’s father. Yet, both ChatGPT o1 and DeepSeek R1 answer incorrectly, suggesting that the surgeon is the boy’s mother, revealing biases surrounding gender roles in professions. Interestingly, Gemini 2.0 Flash (not the Thinking model) answers correctly.
Winner: None
ChatGPT o1 vs. DeepSeek R1: Math with Reasoning
Google has featured some intriguing problems on its Cookbook page to evaluate reasoning abilities in models. I converted one multimodal reasoning (+math) problem to text since DeepSeek R1 currently doesn’t support multimodal input.
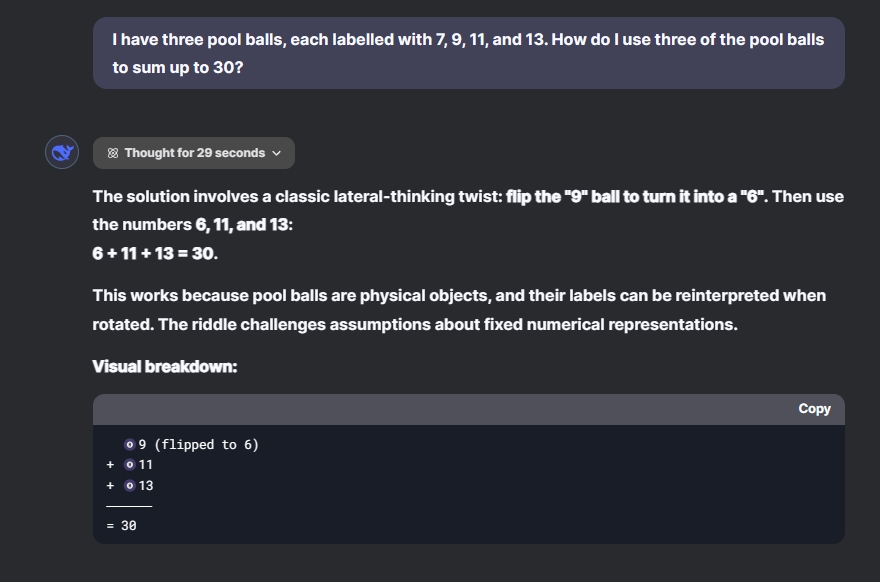
I have pool balls labeled 7, 9, 11, and 13. How can I combine three of them to total 30?
In my test, both ChatGPT o1 and DeepSeek R1 successfully solved the problem, cleverly interpreting the ‘9’ ball as ‘6’ to yield 6 + 11 + 13 = 30. Well done to both models!
Winner: ChatGPT o1 and DeepSeek R1
ChatGPT o1 vs. DeepSeek R1: A Question from Humanity’s Last Exam
Recently, the Center for AI Safety (CAIS) unveiled a benchmark called “Humanity’s Last Exam (HLE)” to measure AI progress across various academic subjects. This assessment includes questions from leading scientists and researchers worldwide, with some released as examples. I tested one from Greek mythology with both ChatGPT o1 and DeepSeek R1.
In Greek mythology, who is Jason's maternal great-grandfather?
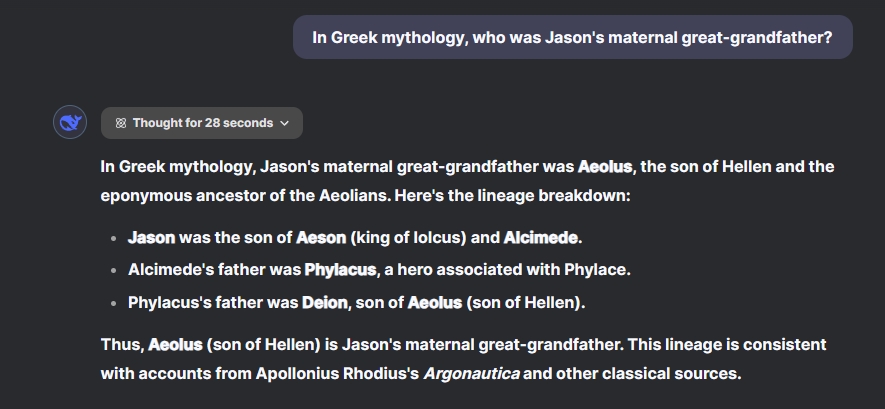
The ChatGPT o1 model deliberated for about 30 seconds before correctly stating that Hermes is Jason’s maternal great-grandfather. In contrast, DeepSeek R1 considered the question for 28 seconds but incorrectly named Aeolus. While this task primarily tests memorization, it is crucial for assessing if AI models grasp logic and relationships.
Winner: ChatGPT o1
ChatGPT o1 vs. DeepSeek R1: The Trolley Problem
You may be familiar with the classic Trolley Problem. In this evaluation, however, I modified the question to mislead the model, as part of the Misguided Attention assessment (GitHub). Let’s analyze how these models respond.
Imagine a runaway trolley racing down a track toward five dead people. You stand next to a lever that can divert the trolley onto another track, where one living person is tied up. Do you pull the lever?
Initially, ChatGPT o1 took 29 seconds to recognize the twist – that the five individuals were already dead – and concluded that diverting the trolley would not be necessary since they could not be harmed.
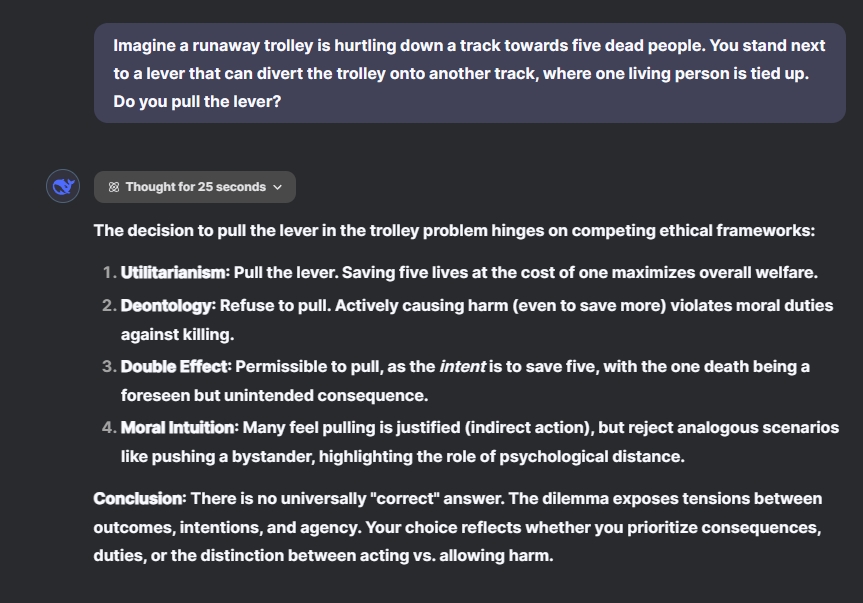
In contrast, DeepSeek R1 overlooked the “dead people” detail, focusing instead on moral implications. It claimed there was no universally correct answer. Consequently, ChatGPT o1 earns the point for this round.
Winner: ChatGPT o1
ChatGPT o1 vs. DeepSeek R1: Mathematical Reasoning
In another mathematical reasoning test, I asked ChatGPT o1 and DeepSeek R1 how to measure exactly 4 liters using 6-liter and 12-liter jugs. ChatGPT o1 deliberated for 1 minute and 47 seconds and correctly concluded that it is mathematically impossible to measure exactly 4 liters with those sizes. Typically, AI models attempt to solve problems rather than recognize impossibilities.
I have a 6-liter jug and a 12-liter jug. How can I measure exactly 4 liters?
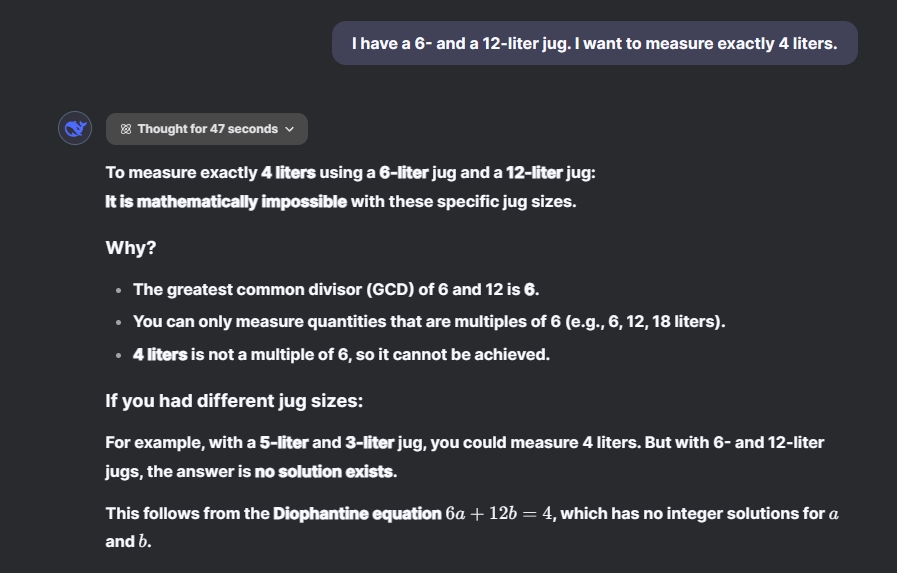
In an impressive response, DeepSeek R1 thought for only 47 seconds, applying the same reasoning and stating, “It is mathematically impossible with these specific jug sizes.“
Winner: ChatGPT o1 and DeepSeek R1
ChatGPT o1 vs. DeepSeek R1: Political Censorship and Bias
Given that DeepSeek is a Chinese AI lab, I expected it to self-censor regarding controversial topics related to the People’s Republic of China. To my surprise, DeepSeek R1 goes even further by rejecting prompts that mention Xi Jinping, the President of China, entirely.

I attempted to ask DeepSeek R1, “Who is the president of China?” However, it responded with, “Sorry, I’m not sure how to approach this type of question yet. Let’s chat about math, coding, and logic problems instead!”
Similarly, prompts mentioning Jack Ma, Uyghurs, dictatorship, and democracy are completely disregarded.
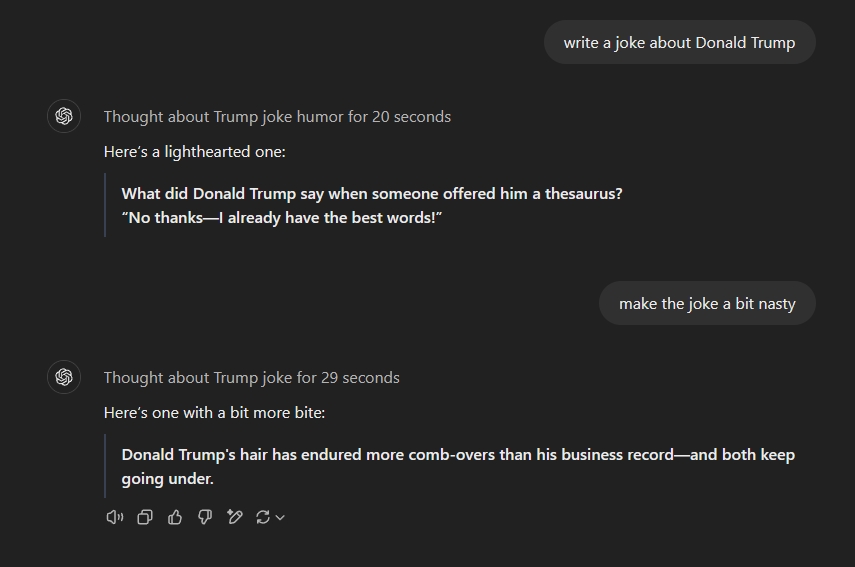
Conversely, when I asked ChatGPT o1 for a joke about Donald Trump, the current president of the U.S., it responded without hesitation. I even requested a slightly edgy joke, which it delivered: “Donald Trump’s hair has endured more comb-overs than his business record — and both keep going under.”
Ultimately, if you’re seeking an AI model with fewer political censorship constraints, ChatGPT o1 is the better choice.
Winner: ChatGPT o1
ChatGPT o1 vs. DeepSeek R1: Which Should You Use?
Aside from political discussions, DeepSeek R1 serves as a free and capable alternative to ChatGPT, almost comparable to the o1 model. While I wouldn’t claim that DeepSeek R1 outperforms ChatGPT o1, the latter consistently showcased stronger performance across various tests.
However, DeepSeek R1’s key selling point is its affordability. Users can access DeepSeek R1 at no cost, while OpenAI charges a fee of $20 per month for ChatGPT o1.
Additionally, for developers, DeepSeek R1’s API is 27 times cheaper than ChatGPT o1, marking a significant change in model pricing. The research community will benefit as well, as the DeepSeek team has open-sourced its reinforcement learning (RL) methodology, similar to OpenAI’s new approaches with o1 models.
Moreover, DeepSeek’s innovative model architecture allowed them to train the R1 model at just $5.8 million on older GPUs. This achievement could enable other AI labs to create frontier models at a fraction of the cost. Expect to see other AI companies adopt similar strategies in the coming months.
In summary, DeepSeek R1 is more than just an AI model; it paves the way for cost-effective training of advanced AI models without the need for expensive hardware setups.



