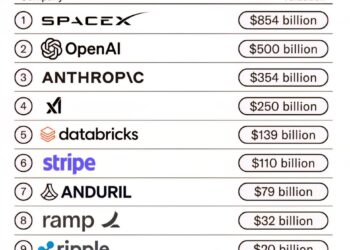
Select Language:
If you need to move objects between buckets within Amazon S3, you don’t have to worry about complicated setups like Transit Gateways. The easiest way is to use the internal CopyObject API method that Amazon S3 provides. You can do this smoothly with the AWS Command Line Interface (CLI).
For example, to copy files from one bucket to another, you can use the command:
aws s3 cp s3://your-source-bucket/folder/ s3://your-destination-bucket/ –recursive –dryrun
Here, the --dryrun option helps you see what would happen without actually performing the move. When you’re ready and everything looks good, remove that part from your command, and the copying will take place.
Remember, if the source and destination buckets are in different AWS accounts, your credentials need specific permissions. You’ll want read permissions (like s3:ListBucket and s3:GetObject) on the source bucket, and write permissions (s3:ListBucket and s3:PutObject) on the destination. If either bucket uses server-side encryption with KMS (known as SSE-KMS), your credentials also need kms:Decrypt and kms:GenerateDataKey permissions for those KMS keys.
For a completely internal transfer within AWS, you can run your CLI commands through AWS CloudShell in the AWS Management Console. This keeps your data within Amazon’s infrastructure, avoiding the need for VPCs, transit gateways, or other network configurations. Even when moving data across different regions, AWS handles it internally, using their backbone network.
It’s best not to download objects to your local system and then upload them to the other bucket—this breaks your goal of keeping data transfer within AWS. Downloading and uploading externally can also require different credentials, complicating your process. Using the internal CopyObject method keeps everything simple, secure, and efficient.