Select Language:
ByteDance has recently announced the commencement of a closed beta for their latest AI video generation model, Seedance 2.0. This advanced system can process a variety of media inputs—including text, images, video clips, and audio—to create complex, autonomous camera movements, all while maintaining consistent character features when the viewpoint shifts.
Seedance 2.0 stands out for its ability to accurately replicate the composition and details of reference images and videos. It can imitate a wide range of cinematic techniques, capturing the nuances of shot transitions, intricate movement sequences, and special effects. Additionally, the platform’s editing capabilities have seen significant improvements, enabling users to replace, add, or remove characters within existing videos seamlessly.
Among early testers of Seedance 2.0, a digital filmmaker with seven years of experience expressed a mixture of awe and concern. He remarked that this model was the only one capable of instilling a genuine sense of fear about the future of film production, suggesting that virtually all roles in the industry might soon be rendered obsolete. Impressively, he noted that Seedance 2.0 could replicate approximately 90% of his learned skills, highlighting its remarkable proficiency.
The buzz around Seedance 2.0 continues to strengthen in investment circles, with many tech and media companies experiencing a surge in stock prices. Notably, companies like Rongxin Culture, Huanrui Century, and Zhangyue Technology have hit daily trading limits, while Zhongwen Online and Jiechengen have opened more than 10% higher than their previous close.
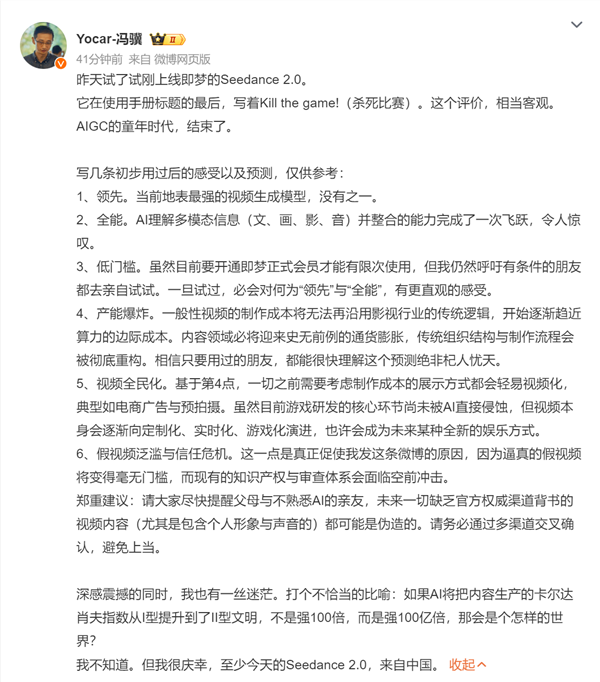
The influence of Seedance 2.0 has caught the attention of prominent industry figures. Feng Ji, the CEO of Game Science and creator of the acclaimed game “Black Myth: Wukong,” recently shared an in-depth article praising the model. He highlighted that Seedance 2.0’s breakthroughs in multi-modal AI understanding mark a significant leap forward and urged interested parties to experience its capabilities firsthand, believing that doing so would provide a clearer sense of what true “leading” and “comprehensive” AI power entail.
Official details reveal that Seedance 2.0 utilizes a dual-branch diffusion transformer architecture, enabling it to generate both video and audio simultaneously. A simple input—either detailed prompts or a single image—can produce a multi-scene video sequence with native sound within 60 seconds. Its unique multi-camera narrative function can automatically produce multiple related scenes from a single prompt while maintaining consistent characters, visual styles, and overall atmosphere without manual editing.
As this technology accelerates, the implications for the entertainment and creative industries are profound, sparking both excitement and debate about the future of human roles in media production.