Select Language:
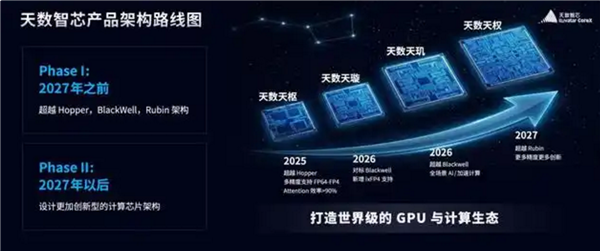
A major development in domestic GPU technology has just been announced, signaling a significant leap forward for China’s semiconductor industry. Chinese company Tianshu Zhixin unveiled its roadmap for the fourth-generation architecture, revealing plans to surpass NVIDIA’s Rubin architecture by 2027.
According to Tang Tianyi, head of AI and accelerator computing at Tianshu Zhixin, their upcoming architectures are designed with ambitious goals. The fourth generation includes the Tianxu architecture in 2025, which aims to outperform NVIDIA’s Hopper (H200 series). The following year, the Tianxuan architecture will target the Blackwell (B200 series), followed by Tianji and Tianquan architectures in 2026 and 2027, respectively, each surpassing their predecessors. After 2027, the company intends to shift focus toward breakthrough computing chip designs that push the boundaries even further.
These advancements come amidst ongoing challenges in the industry, including low energy efficiency, limited creativity, and difficulty deploying high-performance AI solutions. To address these issues, Tianshu Zhixin emphasizes optimizing design to lower overall costs for users while enabling them to handle complex applications with ease. They also highlight the use of precise simulation techniques that allow clients to predict performance beforehand, ensuring reliable deployment. Moreover, their architecture aims for seamless adaptability, supporting the evolution from traditional algorithms to future, possibly unknown, computational paradigms, thereby securing long-term value.
Key technical innovations in the upcoming architectures include support for a broad spectrum of computing tasks—from scientific calculations requiring high precision to AI operations. For example, the Tianxu architecture boasts a remarkable effective utilization rate of over 90% when performing attention mechanism calculations common in AI workloads. The Tianxuan architecture introduces enhanced support for ixFP4 precision, while the Tianji architecture is designed for comprehensive AI and accelerated computing in various scenarios. The Tianquan architecture incorporates further precision support and innovative design elements.
To achieve these goals, Tianshu Zhixin has developed several core technologies. The TPC BroadCast system reduces redundant memory access, improving bandwidth and cutting power consumption. The Instruction Co-Exec system enables multiple instructions to execute simultaneously, boosting performance on complex tasks. Additionally, the Dynamic Warp Scheduling mechanism dynamically manages thread groups to prevent resource conflicts, increasing overall efficiency.
The company’s officials claim that these technological improvements boost the efficiency of the Tianxu architecture by 60% compared to current industry averages. This enhanced performance translates into about 20% higher capabilities in specific AI scenario benchmarks, such as DeepSeek V3, relative to NVIDIA’s Hopper architecture.
During the product launch event, Tianshu Zhixin’s Chairman and CEO, Ge Luxiang, emphasized the importance of fully self-developed, end-to-end AI computing stacks to fortify the ecosystem. He also called for open collaboration and long-term strategic planning to foster a thriving indigenous GPU industry. The company envisions their innovations benefiting various sectors and promoting a robust, domestically driven computing ecosystem.
Prominent Chinese academic Liu Yunjie, a respected member of the Chinese Academy of Engineering, voiced support for the new developments. She stressed that AI computing power must balance scale and quality, extending beyond core data centers to edge devices, covering all application scenarios. Liu praised Tianshu Zhixin’s commitment to independent innovation and ecosystem building over the years, considering it a solid foundation for future growth.
This announcement marks a pivotal step in China’s pursuit of semiconductor independence, showcasing both technical ambition and strategic intent to challenge established global rivals in AI and high-performance computing.




