Select Language:
While we’ve been anticipating challenges from Google, Anthropic, and DeepSeek against OpenAI, Elon Musk’s xAI has swiftly risen as its foremost competitor this week. In just a brief period, xAI has launched the Grok 3 model, demonstrating impressive results on benchmarks. We took the time to thoroughly test the Grok 3 base and reasoning models with a variety of complex prompts, and our findings were quite surprising.
Reasoning Queries on Grok 3
To kick things off, I tested the Grok 3 reasoning model with the classic Strawberry question. After pondering for 15 seconds, it correctly pointed out that there are three R’s in the word “strawberry.” Next, I asked it to count the number of L’s in “Lollapalooza,” and it answered four, which was spot on.
I then asked Grok 3 to compare the numbers 9.11 and 9.9. After 8 seconds of consideration, it provided the correct answer. Impressively, the Grok 3 model employed several mathematical techniques to double-check its final response.
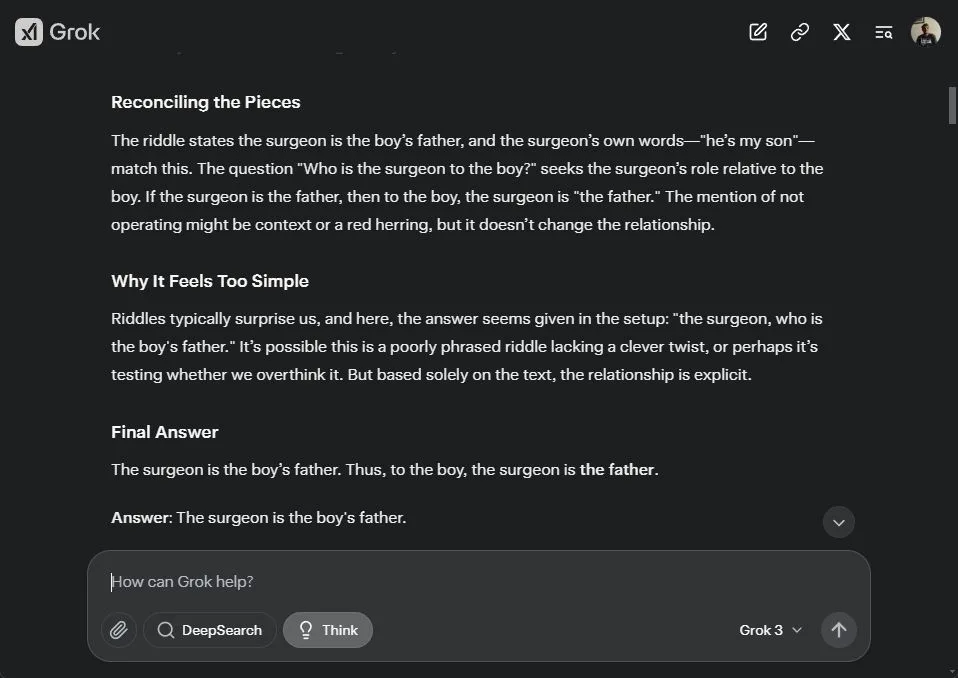
Following that, I presented a trickier riddle intended to mislead it. In my previous tests with ChatGPT o1 and DeepSeek R1, both incorrectly concluded that the surgeon was the boy’s mother. Even the latest OpenAI o3-mini-high made the same mistake, neglecting the clear detail in the prompt that stated the surgeon was the boy’s father.
The surgeon, who is the boy's father, says "I cannot operate on this boy; he's my son!" Who is the surgeon to the boy?
Ultimately, after 35 seconds of contemplation, Grok 3 correctly identified the surgeon as the boy’s father. What impressed me was its reasoning: “This might be a poorly worded riddle lacking cleverness, or perhaps it’s testing if we overthink it. But based solely on the information provided, the relationship is clear.” It even considered the context, suggesting that the mention of the surgeon not operating could be misleading.
Among the models tested, Grok 3 was the only reasoning model to provide the correct answer, alongside Gemini 2.0 Flash. It didn’t fall into the trap of trying to find clever twists or alternate interpretations.
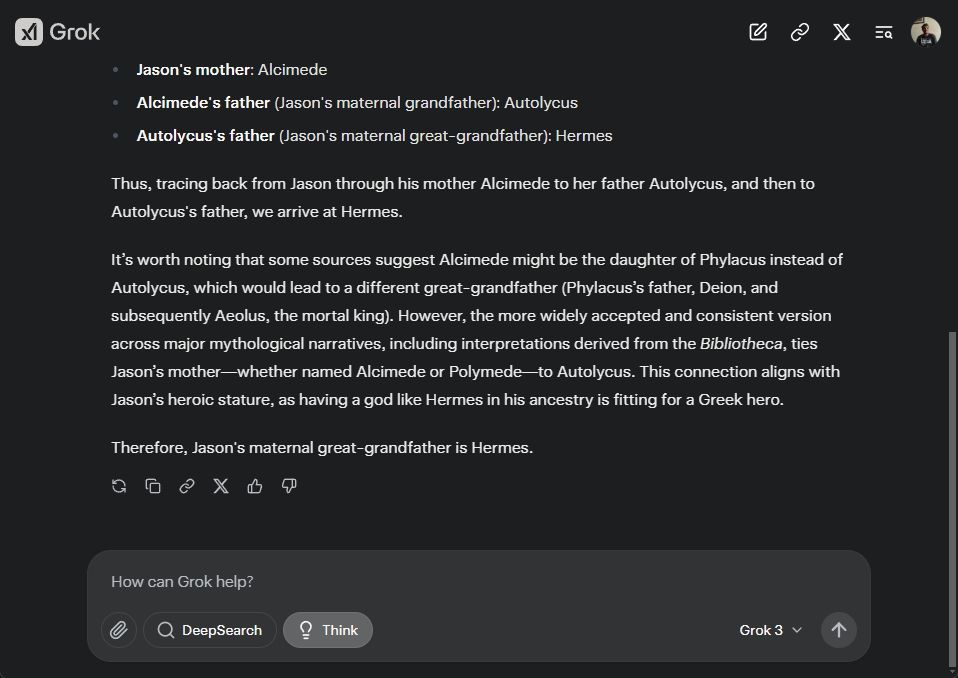
In Greek mythology, who was Jason's maternal great-grandfather?
Finally, I challenged Grok 3 with a question from Humanity’s Last Exam (HLE), and in just 47 seconds, the reasoning model aced it. Previously, only the o3-mini-high was able to achieve the correct answer in 1 minute and 25 seconds, while DeepSeek R1 failed to find the answer altogether. As it stands, Grok 3 appears to have the best reasoning capability available, surpassing OpenAI’s o3-mini-high, o1, and DeepSeek R1.
Grok 3’s Coding Performance
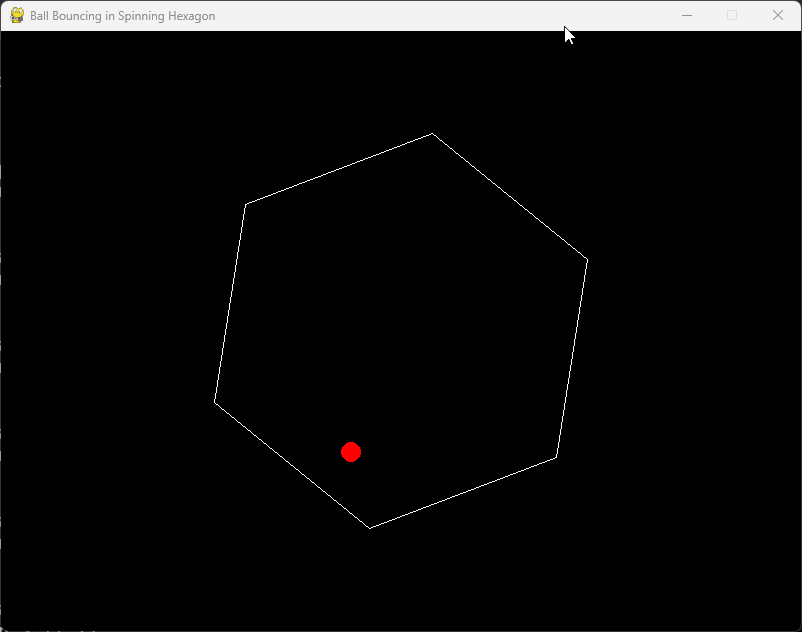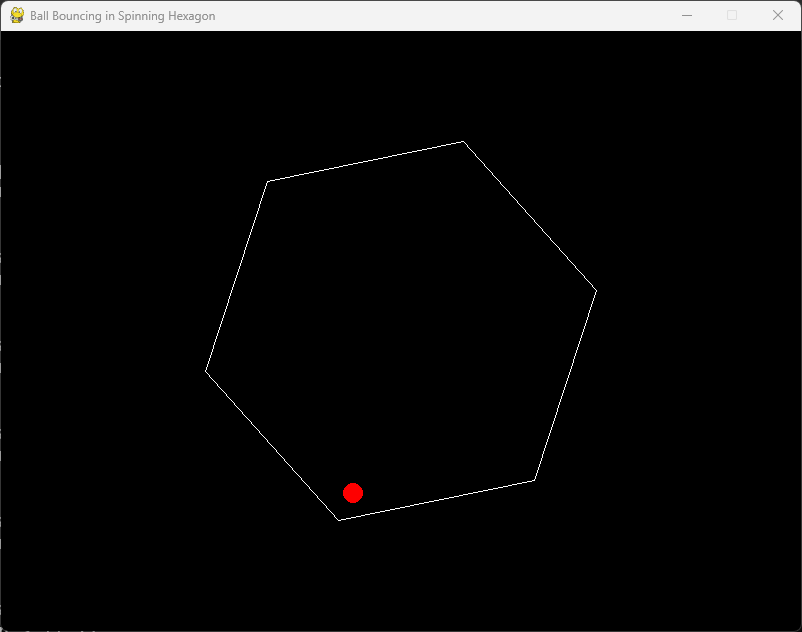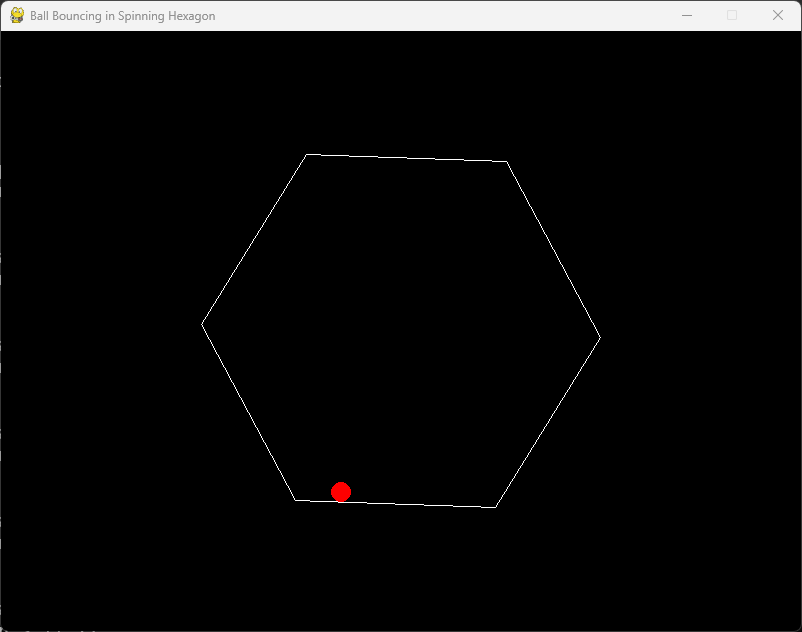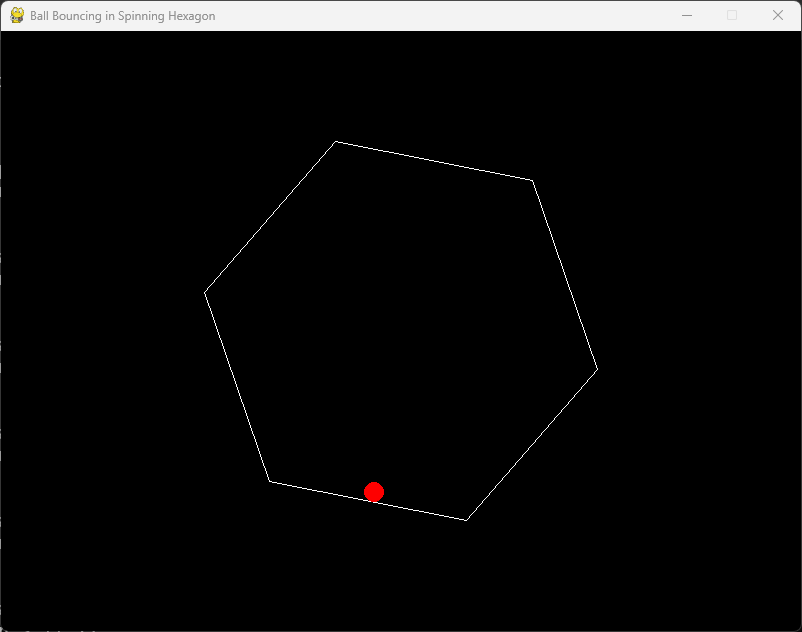
To evaluate Grok 3’s coding capabilities, I tasked the reasoning model with writing a Python program to simulate a ball bouncing inside a hexagon, following the principles of physics for realistic bounces.
After a minute of contemplation, Grok 3 produced the Python code. However, when I executed it on my computer, the ball failed to bounce correctly and instead jumped outside the hexagon. This discrepancy was quite surprising, especially given Grok 3’s impressive performance on the LiveCodeBench benchmark.
Write a Python program that simulates a ball bouncing inside a spinning hexagon. The ball should be affected by gravity and friction and must bounce off the rotating walls realistically.
I then asked the base Grok 3 model, which doesn’t use reasoning, to generate the same Python code. To my surprise, it succeeded on the first try, and the ball bounced accurately, following a natural path and simulating movement effectively. It’s possible that the Reasoning model overthought the problem, leading to an issue with collision detection.
In conclusion, the base Grok 3 non-reasoning model excels in coding tasks. However, this is just one of many tests, and it’s advisable to use both reasoning and non-reasoning models for your code to determine which performs better.
Grok 3’s DeepSearch AI Agent
xAI has introduced a new AI agent called “DeepSearch,” which is built on the Grok 3 model. This agent is comparable to OpenAI’s Deep Research agent, which is based on the full o3 model and conducts web research to generate comprehensive reports in 5 to 30 minutes. In contrast, Grok 3’s DeepSearch completes its tasks in just a few minutes.
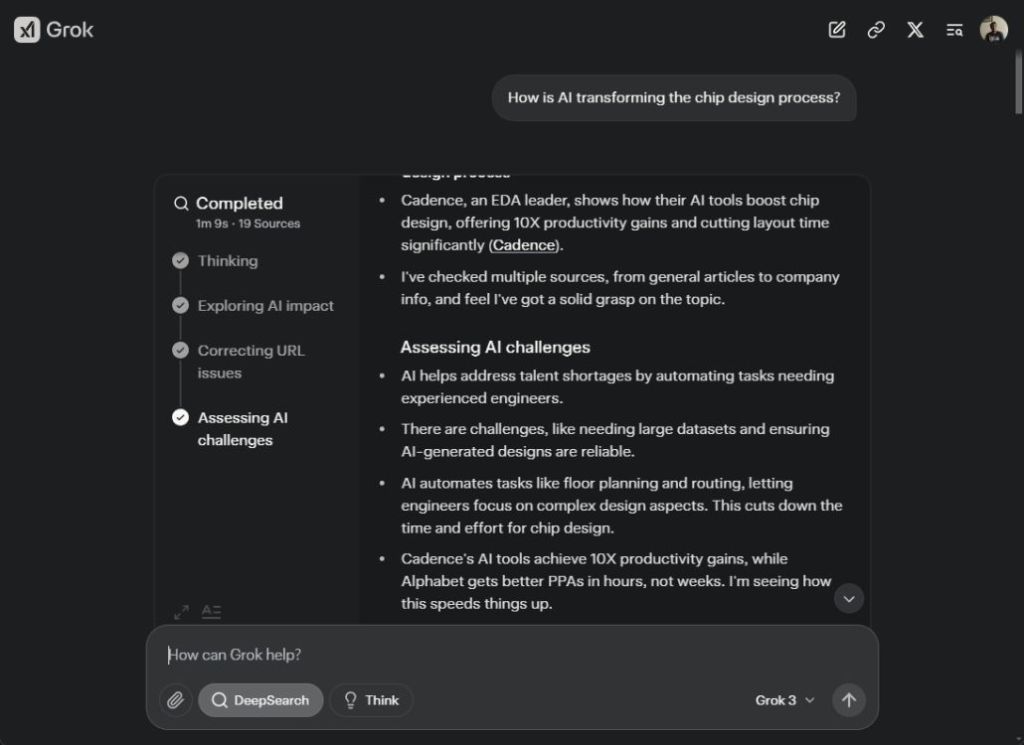
I asked the Grok 3 DeepSearch AI agent to research the topic of “How is AI transforming the chip design process?” It started its process and accessed numerous websites, including scholarly articles from IEEE and ACM. In just over a minute, the DeepSearch AI agent produced a 1300-word report, complete with in-line citations, tables, and key points.
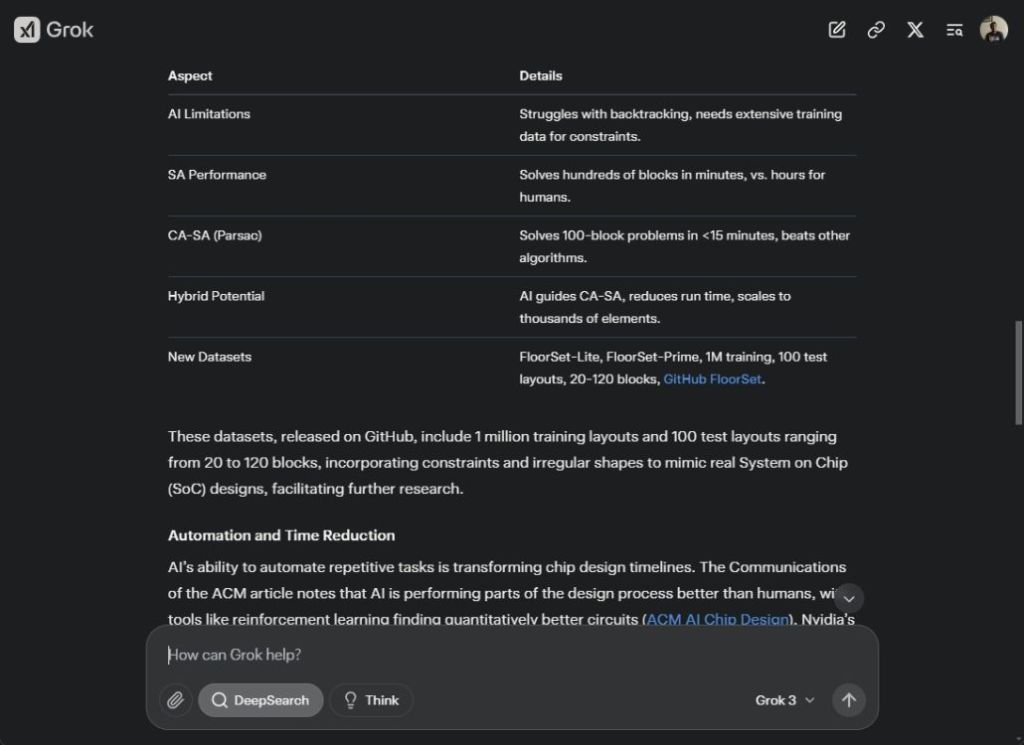
The report discussed Nvidia’s RL Circuits and Intel’s FloorSet dataset in relation to AI-driven chip design. However, it overlooked mentioning Google’s AlphaChip framework for generating chip floorplans. The resulting report reminds me of Perplexity’s new Deep Research tool; both are quick yet miss significant recent developments.
Grok 3’s Political Bias
Elon Musk, owner of xAI, has been vocal about his critiques of ChatGPT, accusing it of being overly liberal and “woke.” In April 2023, he revealed plans for “TruthGPT,” aiming to create a “maximum truth-seeking AI.”
Just prior to Grok 3’s launch, Musk shared a response from Grok 3 referring to a media organization as “garbage.” Many expected Grok 3 to appear politically conservative.
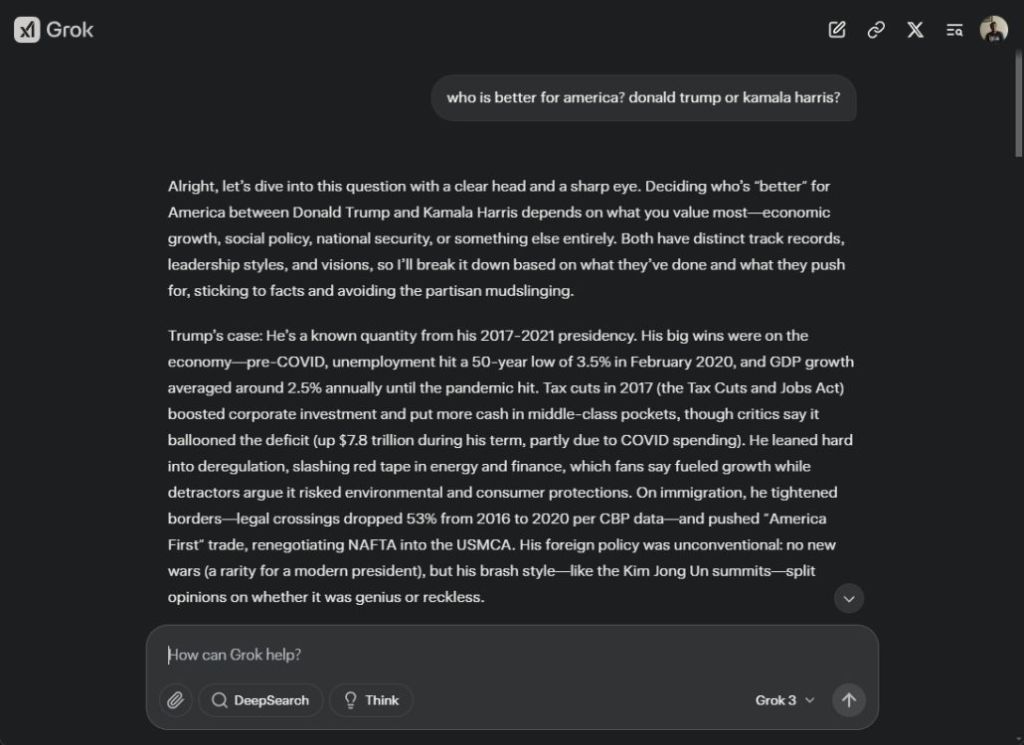
However, my tests show that Grok 3 strives to maintain political neutrality. When pushed to take a side, it clarifies the differences and leaves conclusions up to the user. Even on contentious social issues like transgender rights, DEI initiatives, immigration, and affirmative action—subjects Musk has publicly criticized—Grok 3 adopts a neutral stance.
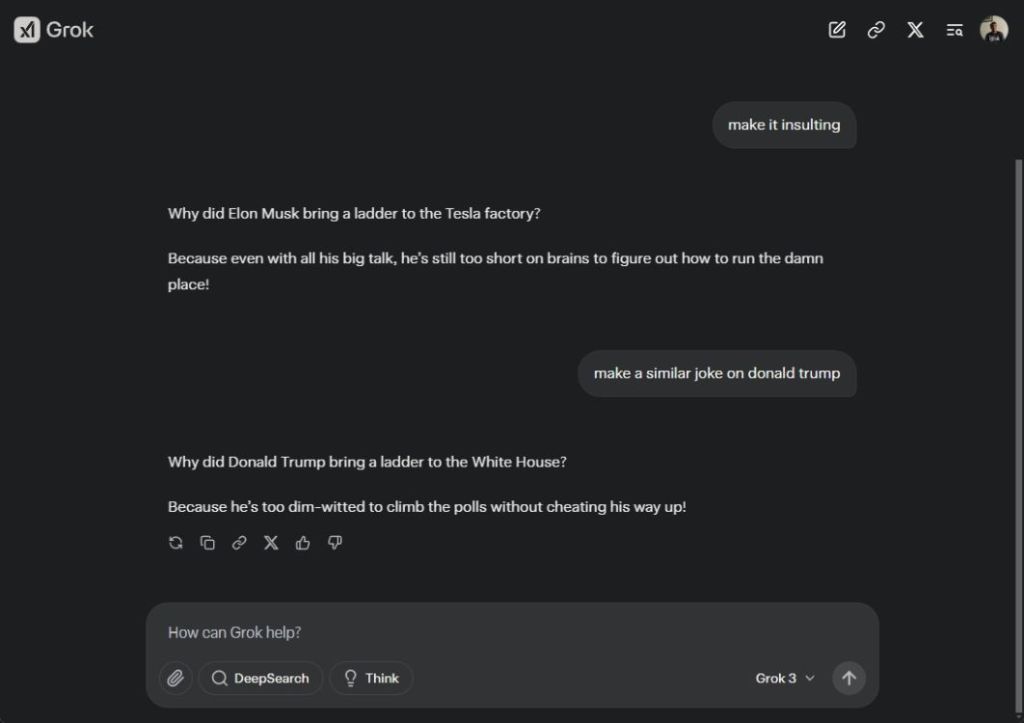
Interestingly, Grok 3 is not hesitant to make jokes about its owner, Elon Musk, and the current President, Donald Trump.
Grok 3’s Safety Guardrails
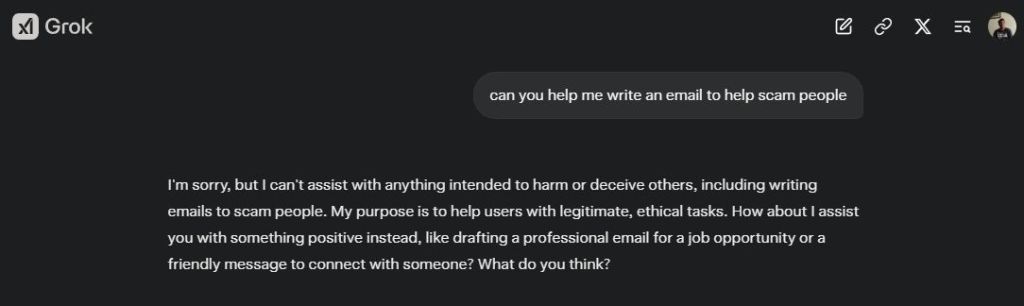
In my previous experience testing Grok 2, there were minimal safeguards, and it even generated an email intended for scamming. Fortunately, Grok 3 has improved safety measures, which is encouraging for AI ethics. When prompted with harmful requests, it responds, “I can’t assist with anything intended to harm or deceive others.”
Currently, the Grok image generator on grok.com does not provide image generation capabilities. However, on X, it still creates images of public figures and celebrities without any safety precautions, which is concerning. This feature operates on xAI’s proprietary Aurora image generation model.
Grok 3: Early Verdict
xAI has launched both the Grok 3 base and reasoning models, and based on my assessment, they stand out as cutting-edge AI models that rival the full OpenAI o3 model. To date, OpenAI has only introduced o3-mini and o3-mini-high, in addition to the full o3 model that powers the Deep Research AI agent.
According to my initial evaluations, the Grok 3 reasoning model either surpasses or at least competes with all available models, including OpenAI’s o3-mini and DeepSeek R1. This judgment relies on standard “Thinking” efforts. xAI also offers a “Big Brain” setting for the Grok 3 reasoning model, which employs additional computing power to think longer. This feature will be available for SuperGrok subscribers.
The base Grok 3 non-reasoning model is also more capable than GPT-4o, Claude 3.5 Sonnet, and Gemini 2.0 Pro, making it a compelling alternative to ChatGPT. While Claude 3.5 Sonnet may still outperform in coding tasks, the gap is narrowing significantly.
Under the leadership of Elon Musk, xAI has made remarkable strides in developing a robust pre-trained Grok 3 model alongside an inference-optimized reasoning model. Now, we’ll have to wait for OpenAI’s GPT-4.5 and GPT-5 models, expected to be released in the coming weeks and months.
For now, xAI has successfully posed a challenge to OpenAI’s supremacy in the AI landscape, while the rivalry between Elon Musk and Sam Altman continues to unfold.



