Select Language:
Google DeepMind has officially launched its most advanced image generation and editing model, Gemini 2.5 Flash Image, according to a recent report from technology media outlet The Decoder. Announced on August 26, the new model enables users to modify images based on textual instructions while maintaining consistent appearances of characters and animals, all with improved precision.
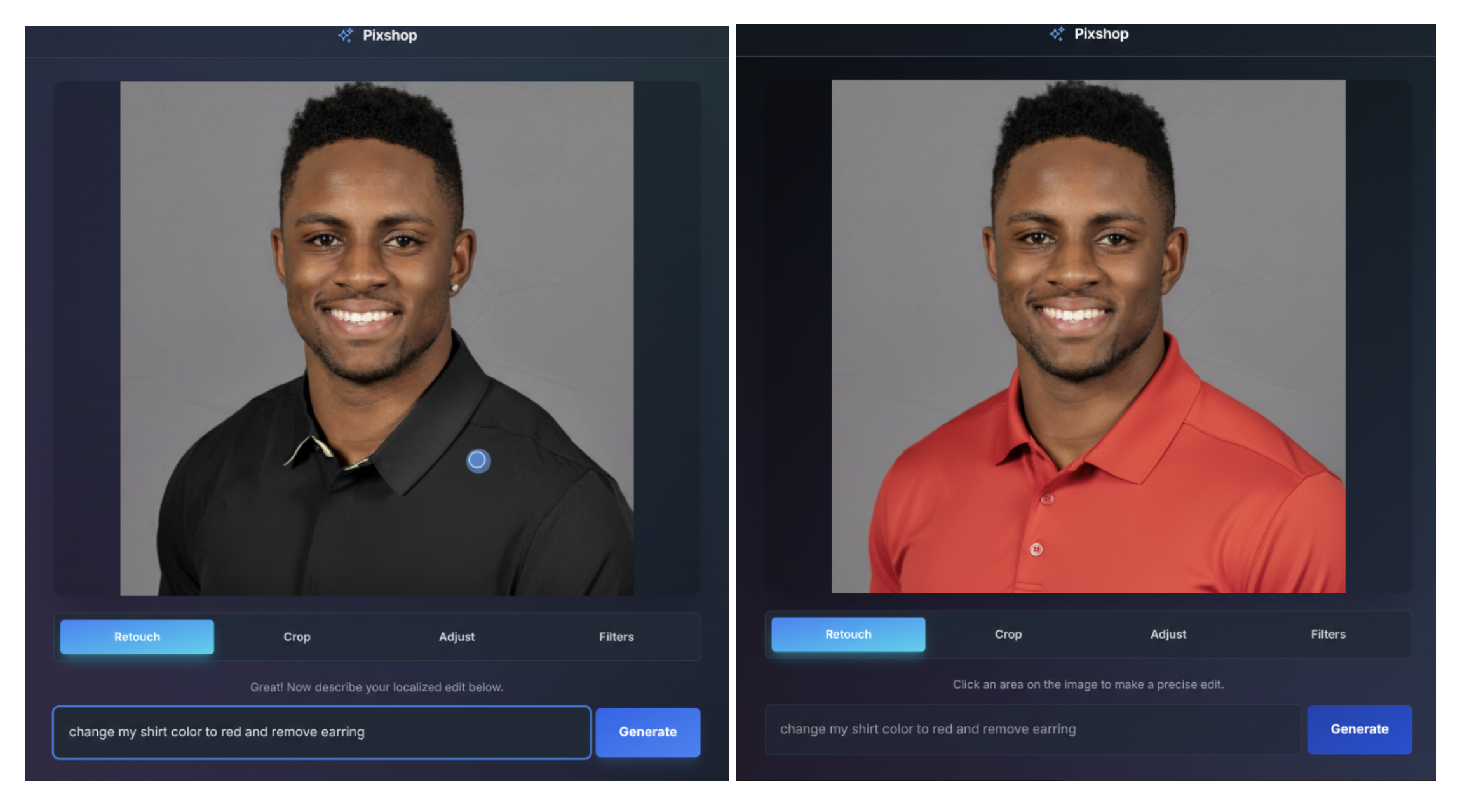
Compared to earlier native image generation tools, Gemini 2.5 Flash Image boasts significantly higher accuracy when editing images through text prompts. Google claims that this model surpasses GPT-4o, the language model used in ChatGPT, especially when it comes to image editing tasks. The model can interpret detailed textual descriptions to make precise alterations in images, marking a notable advancement in AI-driven visual editing.
One of the notable features of Gemini 2.5 is its capability to perform targeted local edits without manual selection. Users can easily blur backgrounds, remove imperfections, add colors, or erase entire objects simply by providing text instructions. Additionally, the model allows for the fusion of up to three images simultaneously, offering more versatility for complex editing tasks.
The model is accessible through the Gemini app and an API, with pricing set at $30 per million tokens generated. For individual images, the cost is approximately 3.9 cents. This offering signifies a meaningful step forward in AI-powered image editing technology, promising more intuitive and accurate results for creators and developers alike.