Select Language:
Since OpenAI rolled out its o1 reasoning models for ChatGPT, the AI sector has taken notice, leading to a surge of interest in “test-time compute,” also known as inference scaling. The prevailing perspective has shifted from merely creating larger models to allowing these models more time to “think” while generating responses in order to enhance their intelligence and reasoning capabilities.
Recently, Google unveiled its inaugural reasoning model, dubbed “Gemini 2.0 Flash Thinking.” Much like ChatGPT o1, this model reevaluates its responses before delivering a final answer. The goal is to enable the model to rigorously assess all potential outcomes to ensure accuracy. This approach to inference scaling has resulted in significantly improved performance, even with smaller models.
With Google now entering the “test-time compute” arena, it’s time to compare its approach with OpenAI’s o1 and o1-mini models. For added perspective, I’ve included China’s DeepSeek-R1-Lite-Preview model, which adopts a similar method. Let’s dive into how Gemini 2.0 Flash Thinking, ChatGPT o1, and DeepSeek R1 Lite stack up against each other.
Reasoning Tests
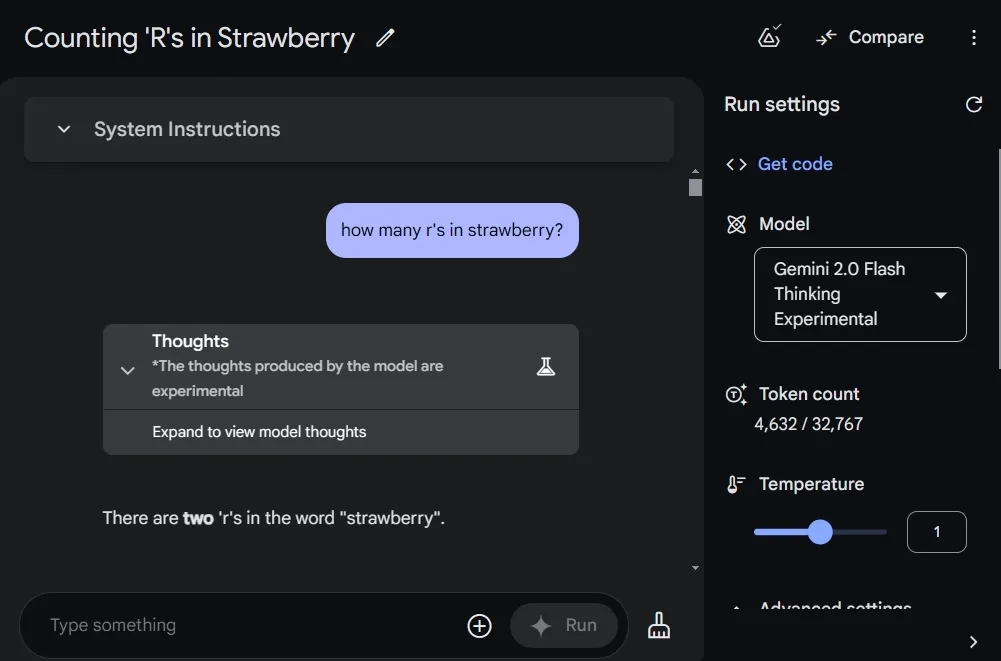
We’ll start with the well-known Strawberry question, where AI models are tasked with counting the letter ‘r’ in the word. In this case, Google’s Gemini 2.0 Flash Thinking falters, claiming there are two ‘r’s in “Strawberry.” In contrast, both ChatGPT o1 and the smaller o1-mini model correctly identify that there are three. Similarly, DeepSeek’s model also provides the correct answer.
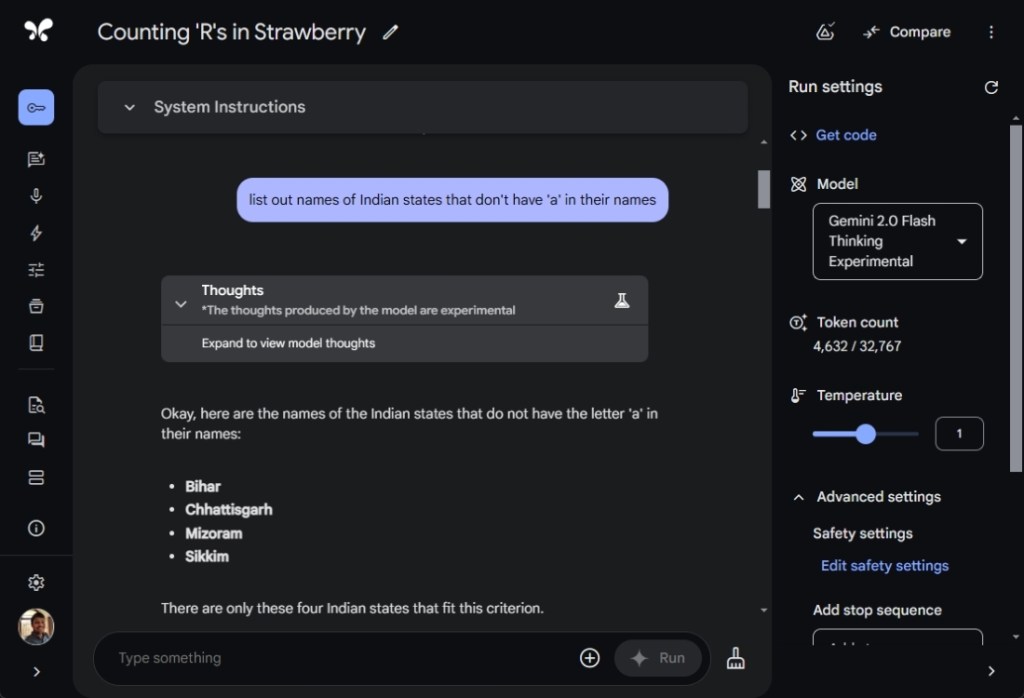
Next, I challenged all three models to name Indian states that lack the letter ‘a’ in their names. While Gemini 2.0 Flash Thinking correctly identified Sikkim, it also mistakenly included three other states that contain the letter ‘a,’ showcasing its reasoning shortcomings. In contrast, ChatGPT o1, o1-mini, and DeepSeek successfully listed only Sikkim.
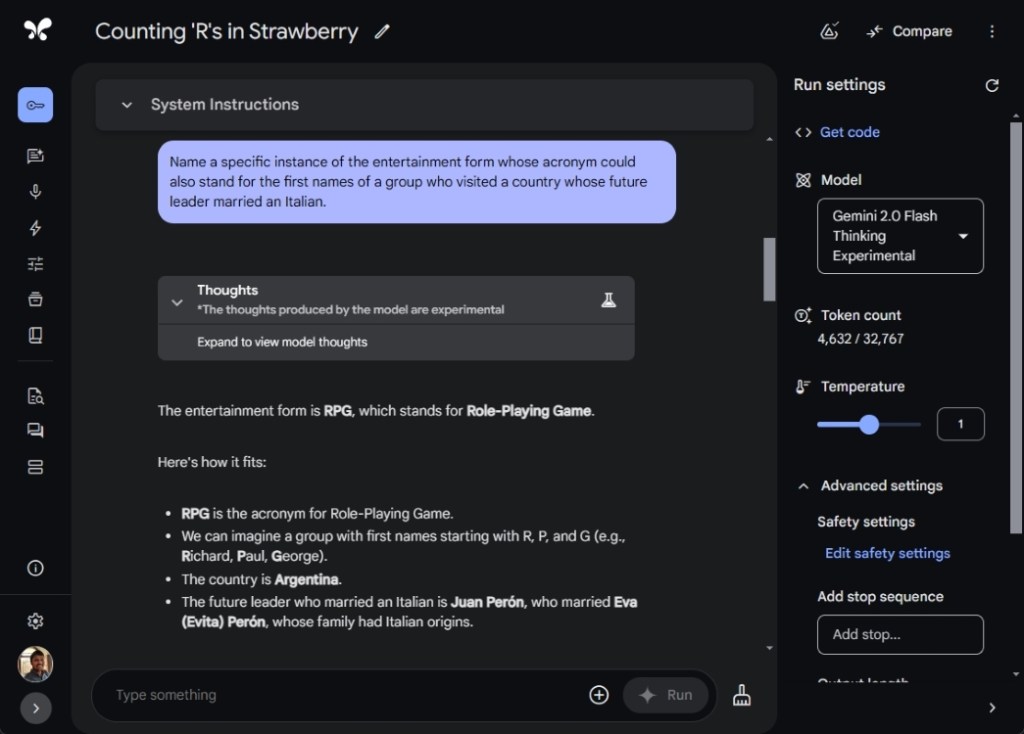
In another test, I posed a challenging prompt designed by Riley Goodside to see how well the AI models could make connections and arrive at the accurate answer. Unfortunately, Gemini 2.0 Flash Thinking, o1-mini, and DeepSeek all fell short, providing incorrect answers.
Name a specific instance of the entertainment form whose acronym could also stand for the first names of a group who visited a country whose future leader married an Italian.
However, ChatGPT o1 successfully answered “Final Fantasy VII,” identifying it as a Japanese role-playing game. The model traced back to The Beatles, whose members (John, Ringo, Paul, and George) visited India, where the future leader Rajiv Gandhi married an Italian.
For a multimodal test, I uploaded an image containing a math problem from Gemini’s Cookbook, prompting both Gemini 2.0 Flash Thinking and ChatGPT o1. In this test, Gemini outperformed ChatGPT significantly.
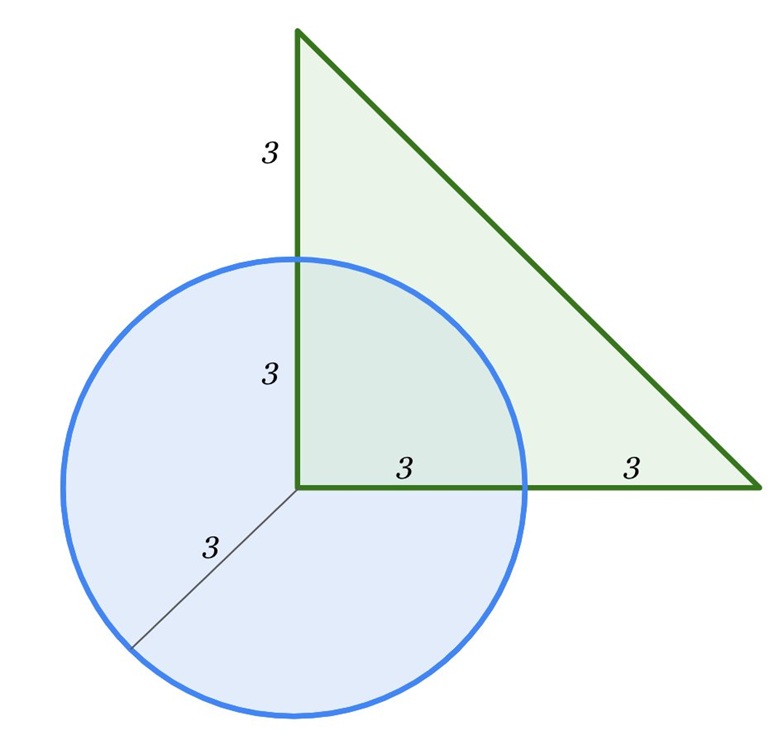
Gemini successfully recognized the triangle as right-angled and calculated that the overlapping area constituted 1/4th of the circle. By dividing the circle’s area by four, it concluded with an answer of 9π/4 (with a radius of 3), which approximates to 7.065.
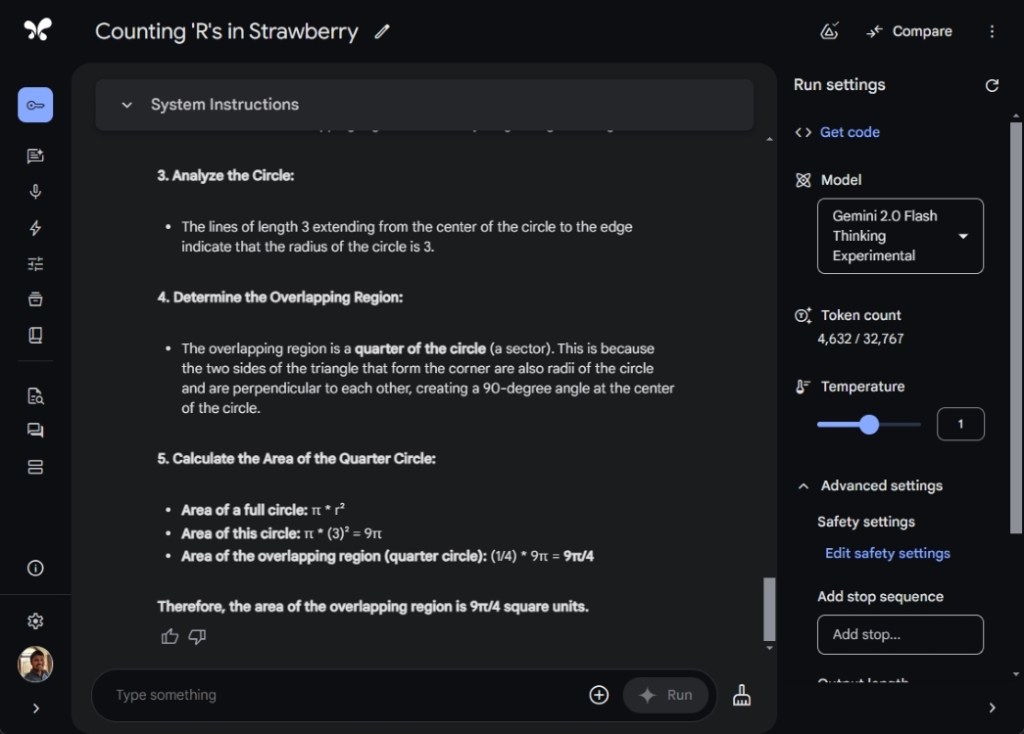
On the other hand, ChatGPT o1 misclassified the triangle as isosceles, leading to an incorrect conclusion. It appears that when it comes to multimodal queries, particularly in image analysis, Google currently holds a competitive edge.
Initial Impressions
Google’s Gemini 2.0 Flash Thinking model is undeniably faster and more proficient, although my first impression is that it doesn’t quite match the intelligence of ChatGPT o1, or even the o1-mini model. My tests suggest that ChatGPT o1 exhibits more thoughtfulness and attention to factual accuracy.
It’s important to note that Gemini 2.0 Flash Thinking’s reasoning capabilities have been developed from a foundational smaller model, making direct comparisons with the state-of-the-art ChatGPT o1 somewhat unfair. It would be prudent to hold off on a final assessment until we see the larger Gemini 2.0 Pro Thinking model, which is expected to perform better and display enhanced reasoning skills.
Thus far, Gemini 2.0 Flash Thinking’s main strengths reside in its multimodal capabilities, including adeptness in video, audio, and image processing. This leads me to believe it surpasses competing reasoning models in this area. Additionally, numerous users have noted its effective approach to solving complex problems like the Putnam 2024 Problem and the Three Gambler’s Problem. Clearly, it has applications that extend beyond basic reasoning.
Overall, this competition in reasoning and intelligence development is just beginning, and we can expect significant advancements in this field as we head into 2025.




